Research Article - International Research Journal of Engineering Science, Technology and Innovation ( 2023) Volume 9, Issue 4
Received: 01-Aug-2023, Manuscript No. irjesti-23-109107; Editor assigned: 04-Aug-2023, Pre QC No. irjesti-23-109107(PQ); Reviewed: 18-Aug-2023, QC No. irjesti-23-109107; Revised: 21-Aug-2023, Manuscript No. irjesti-23-109107(R); Published: 31-Aug-2023, DOI: 10.14303/2315-5663.2023.115
Customers need to be able to talk to businesses in more than one language in the very competitive world of e-commerce. Sentiment analysis is now a vital tool for improving business efficiency and making smart choices. Previous studies on sentiment analysis focused on English, which made it harder to get accurate results from reviews written in English. To make the model more accurate, English reviews were added to a machinelearning model. In a thorough study, accuracy, precision, recall, and F1 scores were used to compare three algorithms. The dataset, which was discovered on Kaggle, was meticulously labeled with positive, negative, and neutral sentiments. After preprocessing the data, machine learning approaches were employed to train the model and evaluate its performance. The accuracy of Multinomial Naive Bayes (MNB) and Random Forest (RF) was 93%, while Decision Tree (DT) was 91%. It was critical to collect and annotate the dataset to ensure its quality and applicability for sentiment analysis algorithms. Experimenting with different algorithms and finetuning hyper parameters may show potential for improvement. For accurate and meaningful results, a broad and representative dataset is required. A greater range of products, sectors, and consumer demographics would boost generalizability. The study on sentiment analysis for English adds greatly to the discipline this research could help English-speaking companies comprehend consumer mood. E-commerce enterprises can better serve customers by improving sentiment analysis. This may provide these companies with a market advantage. The researchers expect the study will impact the e-commerce industry. The objective of this research is to improve sentiment analysis in the e-commerce industry, particularly for customer evaluations written in English. The researchers aim to improve the accuracy of sentiment analysis models by including English reviews in a machine-learning model.
Sentiment analysis, E-commerce review, Machine Learning, Multinomial Naive Bayes, Random forest, Decision tree, TF_IDF extraction
Customers of e-commerce platforms use these types of languages to communicate. In today's competitive business environment, sentiment analysis is extensively used in the e-commerce industry to improve efficiency and business decision-making comprehension. Previous research on sentiment analysis was conducted in English, but there are limitations in model accuracy. Therefore, we have developed a machine- learning model that utilizes reviews written in English and implemented three machine-learning algorithms. We have presented a comparative analysis with prior research and discussed the accuracy, precision, recall, and F1 scores in detail. We have compiled the dataset and categorized all review data as Negative, Positive, and Neutral sentiment. To conduct the analysis, the pre-processed datasets were trained using machine learning techniques, and the performance of the model was evaluated. Multinomial Nave Bayes (MNB) algorithm performed best on the dataset, obtaining 93% accuracy, while the Random Forest (RF) algorithm also achieved 93% accuracy. Decision Tree (DT) obtained an accuracy of 91% (Jiao Y, 2020). Customers' consideration of their merchants and products contributes to the maintenance of their online reputation. Using this active feedback data, shoppers can readily determine which product will be best for them compared to other products. Using contextual data, sentiment analysis is the process of gathering consumer feedback about a product and classifying it into distinct polarities. Text classification is also known as polarity classification. Texts have evolved into a treasury of vital information and diverse perspectives on various topics (You S, 2020). Consumers value the opinions and experiences of others, and the only way to learn what other consumers think of a product is to read reviews. The opinions formed by consumers' experiences with particular products have a direct influence on their future purchases. In contrast, negative and mildly negative ratings frequently result in decreased sales. To achieve business success, proprietors must be able to comprehend their clients' input and correctly polarize vast amounts of data (Tabassum N, 2019). Some studies have only been conducted on the positive, negative, and neutral classes. Human emotions unrelated to the e-commerce industry are the subject of research. To establish a superior e-commerce system, it is necessary to address all forms of consumer-based human sentiment. There is no completed research on the three (Positive, Negative, and Neutral) categories of human sentiment that can be used to develop a more effective electronic commerce business system. This principle motivates us to work on it (Sharif O, 2019). Using three distinct machine learning algorithms, namely Multinomial Naive Bayes, Random Forest, and Decision Tree, this paper intends to detect sentiment based on reviews. The primary objective of this study is to address the limitations of previous research on English product reviews. In the e-commerce review section, there are various types of customer reviews, but working with a limited language and labeling data based on a small number of human emotions can never precisely contribute to the development of a better e commerce system (Soumik MM, 2019). Thus, our primary objective is to polarize all review categories in the review section. This study utilizes information collected from over 23,000 evaluations (Azmin S, 2019).
Hypothesis
The research hypothesis for "Sentiment Analysis on Reviews of E-commerce Websites Using Machine Learning Algorithm" is as follows:
Null hypothesis (h0): There is no significant difference between the efficacies of different machine learning algorithms for analyzing the sentiment of E-commerce website reviews. This null hypothesis suggests that all machine learning algorithms examined will perform similarly when analyzing the sentiment of E-commerce reviews (Wahid MF, 2019). In other words, the algorithm selection will not significantly affect the accuracy and efficacy of sentiment classification.
Alternative hypothesis (ha): The efficacy of various machine learning algorithms for sentiment analysis of E-commerce website reviews varies significantly. The alternative hypothesis asserts that at least one machine learning algorithm will outperform the others on sentiment analysis assignments involving E-commerce review data. It suggests that algorithmic disparities could result in variations in the accuracy and efficiency of sentiment classification (Chowdhury RR, 2019).
Secondary hypothesis (ha2): Utilizing domain-specific characteristics and data preprocessing techniques will enhance the performance of sentiment analysis on Ecommerce reviews. This secondary hypothesis investigates the effect of domain-specific characteristics and data preprocessing techniques tailored for E-commerce review purposes (Sarowar MG, 2019). It is anticipated that tailoring the analysis to the characteristics of E-commerce review data will yield superior sentiment classification results compared to generic methods. Researchers can use statistical analyses and performance metrics to validate or refute these hypotheses based on the outcomes of experiments conducted with different machine learning algorithms and data processing techniques. The objective is to identify the most effective approach for sentiment analysis on E-commerce reviews, which may lead to the development of more accurate and efficient sentiment analysis systems in this domain (Ma Y, 2018).
Research questions
The research query on "Sentiment Analysis on Reviews of E-commerce Websites Using Machine Learning Algorithm" can be stated as follows:
• Can raw data be extracted from the website?
• Can we pre-process the unprocessed data that will be utilized by the Machine Learning techniques
• Can the MNB algorithm be applied to the processed data? Is the Machine Learning process capable of accurately detecting or identifying the category of the provided review dataset?
• How effective are various machine learning algorithms at analyzing the sentiment of E-commerce website reviews, and how can we improve the accuracy and efficiency of sentiment classification for this specific domain? The purpose of these research questions is to investigate the efficacy of various machine learning algorithms in sentiment analysis tasks involving E-commerce website reviews. It seeks to determine how accurately these algorithms can identify and categorize the sentiments expressed in the reviews (e.g., positive, negative, neutral) and to potentially identify any challenges or patterns unique to E-commerce reviews.
Key contributions
The principal contributions of our proposed system are as follows:
• Implementation of the Pipeline method in conjunction with Multinomial Nave Bayes to improve the performance of sentiment detection on ecommerce data.
• Obtaining the algorithm with the highest degree of precision from those already in use.
• Analyze previous studies that employed machine learning for sentiment identification.
Related works in the field of sentiment analysis
According to literature reviews, opinion detection has been studied extensively. However, opinion detection research is extensive. Summarizes literature reviews. Content communities (YouTube, Instagram), social networking (Facebook, LinkedIn), blogs (Reddit, Quora), and micro-blogs (Tumblr) are the four types of social media. E-commerce is the most prominent media platform for collecting user feedback among them [9]. Particularly, e-commerce is a public domain where anyone can view evaluations without permission. In a study, researchers have taken advantage of this opportunity to analyze people's responses to global issues such as climate change. To synthesize the entire content, they utilized word clouds and figured out the frequency of words used in a sentence. During data preprocessing, researchers eliminated irrelevant evaluations to optimize the data and increase the study's relevance. For instance, meaningless monosyllabic reviews are removed, and posts addressing complex topics have been omitted. However, in a different paper [9], researchers recommended lexicon-based approaches for small datasets. In our case, we applied machine learning-based approaches to a small dataset and obtained quite satisfactory accuracy [11, 12]. Collecting data about various users' consent to employ machine learning algorithms to increase business growth by improving product quality. They discovered that the Naive Bayes classifier performed best in predicting sentiment, with an accuracy of 85.50 percent [13]. (Table 1)
| Ref. No | Title of Paper | Authors Name | Year of Publishing | Method | Findings | Limitations |
|---|---|---|---|---|---|---|
| 1 | Sentiment Analysis on বাাংলা রাশিফল (Bengali Horoscope) Corpus | Tirthankar Ghosal, Sajal K. Das, Saprativa Bhattacharjee, Majitar, Rangpo | 2015 | SVM, KNN, RF, DT, LR | SVM is best | Small dataset |
| 2 | Sentiment Analysis of Bengali Texts on Online Restaurant Reviews Using Multinomial Naïve Bayes |
Omar Sharif, Moshiul Hoque, Eftekhar Hossain | 2019 | MNB, RF, DT | MNB is the best | Lack of dataset |
| [3] | Comparative Analysis of Machine Learning Techniques Using Customer Feedback Reviews of Oil and Gas Companies | Layth Nabeel AlRawi, Osama Ibraheem Ashour | 2020 | SVM, NB, IB3, RF, Logistic Boost, Part |
NB accuracy is high |
Limited Scope for small-size of the dataset |
| [4] | Sentiment Analysis in E- Commerce: A Review on The Techniques and Algorithms |
Muhamad Marong Mafas Raheem, Nowshath K Batcha | 2020 | NB- SVM Hybrid model |
The accuracy of the model is 85% | Takes time to compare the long- short snippets. |
| [5] | Sentiment analysis in E- Commerce using Recommendation System | Mr. Kumaran M.E, Ms. L. Monisha, Ms. T. Yamuna, Ms. P. Maheswari, |
2020 | SS3, NB, SVM, KNN | SS3 is best | Time Consuming |
| [6] | Bengali Sentiment Analysis of E- commerce Product Reviews using K-Nearest Neighbors | Mst. Tuhin Akter, Manoara Begum And Rashed Mustafa |
2021 | SVM, KNN, RF, LR | KNN gives the best accuracy | Not enough prior research |
| [7] | Bangla E- Commerce Sentiment Analysis Using Machine Learning Approach | Sunjare Zulfikar, Shukdev Datta, Sifat Momen | 2022 | DT, SVM, RF, SGD, LR | SVM provides high accuracy | Lack of Bangla review data |
| [8] | Sentiment Analysis on Reviews of E- commerce Sites Using Machine Learning | Md Jahed Hossain, Dabasish Das Joy, Sowmitra Das, Rashed Mustafa | 2022 | SVM, DT, MNB, LR, RF, KNN | SVM gives high accuracy | Cannot avoid over- fit data |
| Algorithms |
This research focuses on the automatic classification of e-commerce text utilizing supervised machine-learning techniques to detect users' sentiments. Instrumentation is essential for guaranteeing the authenticity and dependability of the results of this procedure. Through systematic exploration, data analysis, and experimental validation, this framework seeks to gain new knowledge in the area of automatic sentiment detection. The strategic implementation incorporates supervised machine learning techniques, allowing us to accurately classify e-commerce text and contribute to the advancement of this field.
Data collection procedure and sources
The most important factor in attaining the desired outcome is data collection, which requires the application of numerous tools and methods. Obtaining a realistic view of the current world by gazing through the window of collected data makes accurate data collection essential. Fortunately, a substantial portion of the women's e-commerce clothing dataset is publicly accessible, enabling our experiment to utilize it. Due to this availability, constructing a dataset from inception is unnecessary. We can conduct our research and analysis effectively by utilizing the existing women's e-commerce clothing dataset.
Collection process: The data is the primary and most important component for initiating research in any field. Data powers machine learning and deep learning. This study used data from Kaggle [20], a popular portal for community and organization-contributed datasets. Access to a highquality dataset on Kaggle saves time and energy that would have been expended on data collection. With a trustworthy dataset in hand, the focus can transition to data exploration and preprocessing to ensure its accuracy and cleanliness. This preparatory stage is crucial because it directly affects the precision and dependability of the machine learning or deep learning experiments' outcomes. Possessing the appropriate dataset is crucial because it paves the way for deriving meaningful insights and constructing robust models for a particular research field. Utilizing data effectively from the outset significantly increases the likelihood of a productive and fruitful research endeavor (Figure 1). There are 23,000 unique reviews in the dataset, which is organized into ten columns. The unnamed first column presumably functions as an index or identifier for the data entries. The fifth column indicates whether the evaluations are favourable, unfavourable, or neutral. The third column contains age information, which may refer to either the age of the reviewer or the age group targeted by the reviewed products or services. The sixth column contains information regarding the rating assigned to the reviewed products or services.

Figure 1: Sample from dataset.
Data pre-processing: Text documents are composed according to specific linguistic characteristics, including numerous characters, numbers, words, and expression arrangements. However, before feeding the data into a classifier, it is crucial to pre-process the data to satisfy the expected experimental outcomes. The objective of data pre-processing is to represent the data in vector space and eradicate non-informative characteristics. By undergoing this pre-processing procedure, the dimensionality of the vector space can be substantially reduced, resulting in more accurate detection of depression. This dimension reduction optimizes the data representation, making it more suited for the classification procedure. The elimination of noninformative features improves the classifier's ability to recognize pertinent patterns and relationships in the data, thereby enhancing the overall accuracy and performance of sentiment detection (Figure 2).

Figure 2: Dataset after pre-processing.
Tokenization: Table 1 displays tokenization instances for a sample text document. Tokenization is the process of separating a text into individual linguistic entities, or tokens, such as words and sub words. Each token is a fundamental building element for tasks involving natural language processing.
Consider the tokenization examples in Table 2
| Derived Words | Root Words |
|---|---|
| Days | Day |
| Saw | See |
| Thinking | Think |
| Sentiments | Sentiment |
Have a great day" is a sample of a text document. ['Have', 'a', 'great', 'day'] Tokenized document.
In this example, the text is tokenized into four tokens: 'Have', 'a, 'great', and 'day', where each word is regarded as a distinct token.
"I do not need to build any dataset" is an example of a text document. ['I', 'do', 'not', 'need', 'to', 'build', and ‘any ‘,’ dataset] Tokenized document.
In this example, the text is tokenized into eight tokens, one for each original term. The text must be tokenized before being fed to natural language processing models. Tokenization enables the model to operate with discrete text units and improves the analysis and comprehension of linguistic structures and patterns.
Removal of punctuation words: In numerous tasks involving natural language processing, punctuation marks and certain symbols in tweets and other texts are frequently deemed extraneous for analysis or modeling. These symbols may introduce confusion and make it more difficult for models to extract relevant information from text. To produce a clean dataset, it is common practice to exclude or remove them during the data preprocessing phase. The following punctuation marks and symbols are typically omitted at this stage: >: [ ] & * () | @ Angle brackets, colons, square brackets, caret, ampersand, asterisk, parentheses, and the "@" symbol are frequently omitted because they lack significant semantic significance in many contexts. Commas, periods, question marks, exclamation points, and others may be eliminated depending on the analysis or modeling. These punctuation marks may be useful in sentiment analysis, therefore their omission may depend on the goal. The removal of white spaces, tabs, and newlines standardizes the text and ensures that tokens are appropriately separated without the introduction of extra spaces. By removing these irrelevant symbols and punctuation marks, the text data is transformed into a cleaner representation, making it simpler for models to analyze the text and extract meaningful patterns. This preprocessing phase is essential for numerous NLP tasks, such as text classification, sentiment analysis, and named entity recognition. It helps improve the quality of the dataset and boosts the NLP models' overall performance (Figure 3).

Figure 3: Boxplot with encoded value vs length.
Digit removal: In many natural language processing tasks, such as the analysis of tweets, numeric texts (numbers) in English that have no significant meaning may be eliminated to reduce data redundancy and noise. In tweets, numbers frequently represent quantities, dates, times, or other numerical values, and they may not significantly contribute to the context or sentiment of the text (Figure 4).

Figure 4: Boxplot with rating vs length.
Stemming: Stemming and lemmatization are important preprocessing tasks in natural language processing (NLP) that help normalize words by reducing them to their base or root forms. Stemming involves removing prefixes and suffixes from words, resulting in truncated forms of the original words. On the other hand, lemmatization considers the part of speech of each word and provides a more meaningful reduction to the base or dictionary form of the word. The primary benefit of performing these preprocessing tasks is the normalization of words, which helps to bring together various inflections of the same root word. This simplifies the data and reduces redundancy in the text. Additionally, these processes can significantly improve the performance of various NLP tasks, such as sentiment analysis, information retrieval, and machine learning-based text classification. By reducing words to their base forms, stemming and lemmatization make it easier for NLP models to recognize and generalize patterns in the text, leading to more accurate and efficient analyses and predictions (Table 3) (Figure 5). In this instance, lemmatization, particularly in the context of noun suffixes, is the focus. By analyzing and reducing nouns to their lemma forms, it is possible to create a more organized and compact corpus, thereby enhancing the efficacy and generalization of NLP applications.
| Categories | Words Example |
|---|---|
| Postpositions | [ ‘pm’, ‘night’, ‘day’ ] |
| Conjunctions | [ ‘and’, ‘but’ ] |
| Interjections | [‘still’, ‘really’] |

Figure 5: Positive word cloud.
Stop Words Removal: Stop words are frequently used words that serve primarily to construct the structure and improve the linguistic qualities of a sentence (Figure 6).

Figure 6: Negative word cloud.
However, the excessive use of these words does not add significant information to the text; rather, it increases the frequency of occurrence, resulting in a greater number of dimensions in the data. As shown in the table below, English stop words can be divided into the following categories (Table 4)
| Serial | Algorithm | Accuracy |
|---|---|---|
| 01 | MNB | 0.93 |
| 02 | DT | 0.91 |
| 03 | RF | 0.93 |
Feature extraction & selection
In MNB, "dimensionality" refers to the number of features (i.e. input variables) in the dataset. When the model predicts the middle word based on the context words surrounding it. A few syllables immediately precede and follow the current (middle) word. This architecture is referred to as a bag-of-words model because the context- dependent order of words is irrelevant. In this fashion, the most popular method, Word2Vec, is used. This is discussed further below.
Word2vec method
Word2vec is a natural language processing technique published in 2013. The word2vec algorithm learns word associations from a large corpus of text using a neural network model. Once trained, such a model can identify synonyms and suggest additional terms for a sentence fragment. Word2Vec is effective due to its capacity to arrange together vectors of similar words. Word2Vec can make accurate estimates of a word's meaning based on its occurrences in text, given a large enough dataset. These estimations produce word associations with other corpus terms. For instance, the terms "King" and "Queen" are extremely similar. When performing algebraic operations on word embedding’s, it is possible to discover an approximation of word similarity. For instance, the 2-dimensional embedding vector of "king" minus the 2-dimensional embedding vectors of "man" plus the 2-dimensional embedding vector of "woman" resulted in a vector that is very near to the embedding vector of "queen." Note that the following values were selected indiscriminately.
King - Man + Woman = Queen [5, 3] - [2, 1] + [3, 2] = [6, 4]
The primary benefits of selecting this feature are Ease of computation; Simple metric to extract the most descriptive terms from a document.
Proposed model
Depression detection using supervised machine learning (ML) typically involves a classification approach, where the goal is to train a model to predict whether a person is suffering from depression based on input features derived from various sources such as text, audio, or physiological signals [9] (Figure 7).

Figure 7: Proposed model.
Various sampling strategies exist for comparing algorithms. Training set validation, percentage split validation, and crossfold validations are the three most prominent techniques among them. I used two distinct methods to conduct my experiment: one is the percentage split validation approach [10]. In our dataset, there are 23000 reviews for each of the two categories. Of these, approximately 18400 reviews were kept for the training set, while 4600 reviews were used for testing (Figure 8). This dataset includes two distinct data level categories. Positive, neutral, and negative are their names. Here we have 1 for Positive, -1 for Negative, and 0 for Neutral. In this Kaggle dataset, there are approximately 1333 Negative records, 21213 Positive records, and 95 Neutral records [11] (Figure 9).

Figure 8: Pie chart for sentiment.

Figure 9: Dataset levels distribution.
Different criteria and metrics are used to estimate how well different supervised learning techniques including deep learning perform in detecting depression. Popular performance measures including recall, precision, and F-measure (F1) with accuracy scores are used to simplify my experiment [12].
Precision is the proportion of our pertinent findings. Recall, on the other hand, is the proportion of all relevant results that the algorithm properly identified as relevant. The capacity of any approach to accurately determine all results on the entire set of provided documents is referred to as accuracy [13]. For a given set of tweets, accuracy can be defined mathematically as:
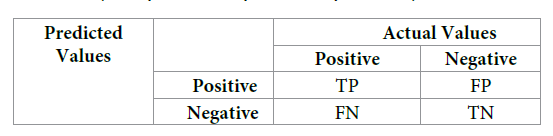
Accuracy (all correct / all) = TP + TN / TP + TN + FP + FN Precision (true positives / predicted positives) = TP / TP + FP
After conducting sentiment analysis experiments using supervised machine learning algorithms, we achieved high accuracy by running 50 epochs. The Training and Validation Accuracy value graph illustrates the model's performance during training, with the red line representing Validation Accuracy and the blue line representing Training Accuracy. As the number of epochs increases, the model's performance on the training data (blue line) improves since it learns from the training dataset and minimizes the training loss. Meanwhile, the validation accuracy (red line) reflects the model's generalization to unseen data on a separate validation dataset. Regarding the experimental results, we implemented sentiment analysis using two different approaches [14].
Approach 1 involved employing specific supervised machine learning algorithms, and after 50 epochs, we obtained accurate results for both the training and validation datasets. By analyzing the Training and Validation Accuracy value graph, we assessed the model's behavior and looked for signs of over fitting or under fitting [15].
Approach 2 was distinct from the first approach, with variations in algorithms, preprocessing, or feature engineering. Similar to Approach 1, we evaluated and compared the accuracy results on the training and validation datasets for Approach 2. The comparison of the two approaches revealed insights into their performance and generalization capabilities. Additionally, we considered other evaluation metrics like precision, recall, F1 score, and confusion matrix, especially if the dataset had class imbalances [16].
Providing detailed explanations and clear interpretations of the results was crucial to comprehensively understand the outcomes of the sentiment analysis experiments. Visualizations, such as the Training and Validation Accuracy value graph, played a significant role in illustrating performance trends and aiding in result analysis [17] (Figures 10-12). The Multinomial Nave Bayes (MNB) classifier had a 93% accuracy rate, according to the results of the sentiment analysis utilizing machine learning methods. With an accuracy of 93%, the Random Forest (RF) classifier also did well. The Decision Tree algorithm, however, had the lowest accuracy of the three algorithms with a 91% score, making it the least accurate [18].

Figure 10: Multinomial Naïve Bayes classification report in sentiment analysis using ML approach.

Figure 11: Decision tree classification report in sentiment analysis using ML approach.

Figure 12: Random forest classification report in sentiment analysis using ML approach.
The higher performance of the MNB and RF classifiers in comparison to the Decision Tree approach is further supported by the tabular and graphical representations of the data. As shown in the plots, MNB and RF performed more accurately than the Decision Tree [19] (Table 4) (Figure 13).

Figure 13: Comparison of classification result.
Undoubtedly, there has been a lot of research done on sentiment analysis, particularly when it comes to e-commerce review data. There has recently been an increase in studies in this area as a result of the research's obvious revolutionary effects on our digital lives. Unfortunately, there hasn't been much research on sentiment analysis in Bangla, which is sad. However, there is optimism because scientists have begun investigating this area in many different nations [20].
The primary findings from our research, where we used a variety of classification methods to classify review categories, are as follows:
• By adopting a comparative supervised learning strategy, we were able to analyze sentiment using the MNB (Multinomial Naive Bayes) and RF (Random Forest) algorithms with an outstanding accuracy of 93%.
• The decision tree (DT) method, in contrast, has a slightly lower accuracy of 91%.
These results show the potential of sentiment analysis in the Bangla language and emphasize the need for more study in this field to transform our knowledge and use of sentiment analysis in computing [21].
Although we recognize in our study that the accuracy level of the employed algorithms may not be perfect, the research has been incredibly instructive. We have learned a lot about working with e-commerce review data, mastering the preparation of raw data, and successfully using machine learning algorithms on our trained dataset as a result of this project [22]. Despite these restrictions, we think that future scholars looking into sentiment analysis in this area will find our findings to be quite useful. In our research, we present an approach for opinion detection from review data using several machine learning methods. This method provides a generalized framework for prediction and recommendation that can be used with different datasets and exhibits reasonable accuracy [23]. It is crucial to stress that additional research could considerably improve the outcomes. Notably, in our studies, the Random Forest classifier produced the best accuracy score of 93%. However, to get even greater performance, we intend to investigate other classifiers in upcoming work [23]. We intend to offer a helpful resource for upcoming scholars interested in sentiment analysis by disclosing our technique and findings. Although the accuracy levels at this time may not be optimal, the knowledge obtained from this study paves the path for future advancements and more complex methods of handling e-commerce review data [24]. We believe that sentiment analysis in the context of e-commerce may be pushed further with sustained research and experimentation, advancing both academia and industry [25]. The focus of future sentiment analysis research will be on cutting-edge methods for automating deep learning and machine learning applications in review sentiment analysis. Automating the procedure and producing frequent reports to track sentiment spread are the objectives [26]. Considering that Natural Language Processing (NLP) is still in its infancy, we predict more advanced algorithms in the future that will strive for greater accuracy while working with massive amounts of data [27]. The present classification algorithms might be improved by adding a new category for people who are susceptible to impending changes in review sentiment. However, sentiment analytics programs and NLP technologies intended for formal language face difficulties when dealing with the informal language present in e-commerce reviews [28]. Overcoming these problems is essential, and we anticipate the development of new NLP and machine learning algorithms that can comprehend and evaluate such informal material, particularly for the diagnosis of depression in e- commerce evaluations [29].
Indexed at, Google Scholar, Crossref
Indexed at, Google Scholar, Crossref
Indexed at, Google Scholar, Crossref
Indexed at Google Scholar Crossref
Indexed at, Google Scholar, Crossref
Indexed at, Google Scholar, Crossref
Indexed at, Google Scholar, Crossref
Indexed at, Google Scholar, Crossref
Copyright: ©2023 International Research Journals This is an open access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.